TiDB 国产分布式数据库的架构特性与数据处理存储服务解析
在数据库技术日新月异的今天,国产分布式数据库TiDB凭借其独特的架构设计和强大的数据处理能力,在众多场景中脱颖而出。它不仅融合了传统关系型数据库的事务处理优势,还具备了NoSQL系统的水平扩展能力,为现代应用提供了高可用、强一致且弹性伸缩的数据服务。本文将深入解析TiDB的核心架构特性,并探讨其数据处理与存储服务的关键机制。
一、TiDB的核心架构特性
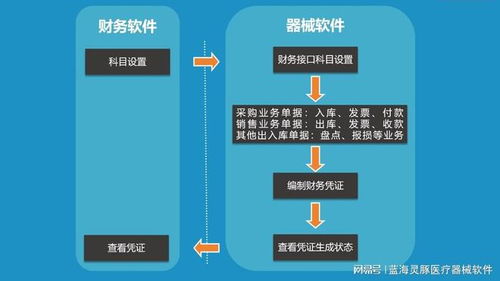
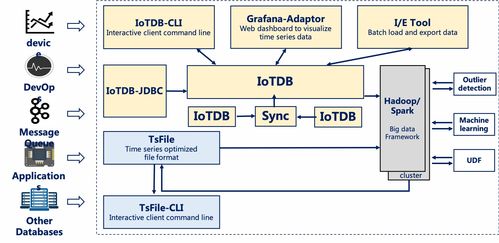
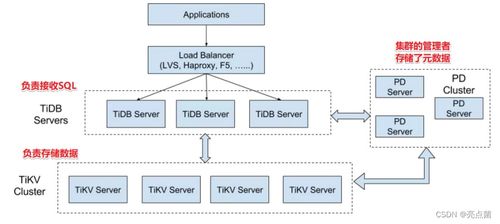
TiDB的整体架构采用了分层设计,清晰地分离了计算与存储,主要由三个核心组件构成:TiDB Server、TiKV和PD(Placement Driver)。
1. 计算层:TiDB Server
TiDB Server是无状态的计算节点,负责接收SQL请求,进行语法解析、查询优化并生成分布式执行计划。它本身不存储数据,而是通过与存储层TiKV的交互来获取或修改数据。这种无状态设计使得计算层可以轻松地水平扩展,通过增减TiDB Server实例来应对变化的业务负载,实现了计算资源的弹性调度。
2. 存储层:TiKV
TiKV是TiDB的分布式键值存储引擎,是整个系统的数据持久化核心。它将数据以Region(一个连续的数据范围)为单位进行分片,并利用Raft一致性协议将每个Region复制到多个节点上,从而保证了数据的强一致性和高可用性。TiKV采用LSM-Tree结构存储数据,具备出色的写入性能,并通过MVCC(多版本并发控制)机制支持高并发的读写事务。
3. 调度层:PD(Placement Driver)
PD是整个集群的“大脑”,负责元数据管理和全局调度。它存储了整个集群的元信息(如Region的分布、TiKV节点状态等),并根据负载情况、数据均衡和故障恢复等策略,动态地调度Region在TiKV节点间的迁移。PD还负责分配全局唯一且递增的事务ID和时间戳,为分布式事务提供了全局有序的时钟服务。
这种“计算-存储分离”的架构,使得TiDB能够独立地对计算资源和存储资源进行弹性扩缩容,既满足了OLTP(在线事务处理)场景的低延迟需求,也兼顾了OLAP(在线分析处理)场景对海量数据处理的需求。
二、数据处理与存储服务详解
TiDB在数据处理与存储方面,提供了强大而灵活的服务能力。
1. 分布式事务处理
TiDB支持完整的分布式ACID事务,默认隔离级别为可重复读(Repeatable Read)。其分布式事务模型基于Google的Percolator协议,并进行了优化。事务的提交是一个两阶段提交(2PC)过程,由TiDB Server协调。通过PD提供的全局时间戳服务,TiDB实现了乐观锁机制,避免了传统分布式事务中常见的锁竞争问题,提升了并发处理能力。TiDB也支持悲观事务模式,以适应对数据冲突较为敏感的场景。
2. 弹性伸缩的存储服务
得益于TiKV的分布式架构,TiDB的存储容量和吞吐量可以近乎线性地扩展。当需要扩容时,只需向集群中添加新的TiKV节点,PD会自动将部分Region从负载较高的节点迁移到新节点上,实现数据的自动再平衡,整个过程对业务透明。这种设计使得TiDB能够轻松应对数据量和访问量的持续增长。
3. 多副本与高可用
数据在TiKV中以多副本(默认3副本)的形式存储在不同的物理节点上,并通过Raft协议保证副本间的一致性。当任何一个副本所在的节点发生故障时,Raft协议能够自动选举新的Leader并恢复副本数,确保服务不中断、数据不丢失。PD会感知节点的状态变化并触发相应的调度,如补充副本或将Leader切换到健康的节点上,从而实现金融级的高可用性。
4. 与生态的无缝集成
在数据处理层面,TiDB兼容MySQL 5.7协议和大多数语法,这意味着现有的MySQL客户端、驱动、ORM框架以及数据迁移、备份工具几乎无需修改即可接入TiDB,极大地降低了用户的迁移和运维成本。TiDB可以通过TiFlash(列式存储引擎)组件提供实时HTAP(混合事务/分析处理)能力,一份数据既能支持高并发的事务处理,也能进行复杂的实时分析查询。
###
TiDB作为国产分布式数据库的杰出代表,其创新的分层架构将计算与存储解耦,通过TiDB Server、TiKV和PD三大组件的协同工作,构建了一个既具备弹性伸缩、高可用特性,又保持强一致性和完整SQL支持的数据库系统。其在分布式事务、弹性存储、多副本高可用等方面的精心设计,使其能够从容应对大数据时代下海量数据、高并发访问和复杂业务逻辑的挑战。随着技术的不断迭代和生态的日益完善,TiDB正成为企业构建核心数据平台、实现数字化转型的重要基石。
如若转载,请注明出处:http://www.xinyuan-technology.com/product/69.html
更新时间:2026-06-19 05:30:44