IoTDB学习笔记 数据处理与存储服务核心解析
概述
Apache IoTDB(物联网数据库)是一款专为物联网时序数据设计的高性能数据库管理系统,其核心优势在于高效的数据处理与存储服务。本文将从数据处理流程与存储架构两个维度,系统梳理IoTDB的关键机制。
一、数据处理服务
数据处理是IoTDB接触数据的首要环节,主要包括写入、查询与预处理。
1. 数据写入流程
写入路径遵循“接收-验证-排序-持久化”的流程。
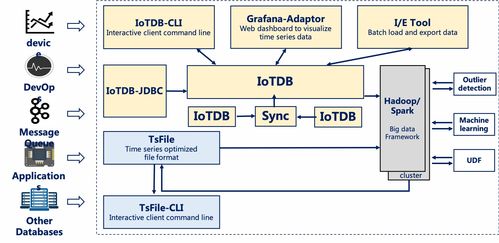
- 接口层:支持多种协议接入,如原生API、MQTT、HTTP RESTful及JDBC,便于设备或应用直接写入时序数据点。
- 验证与排序:数据到达后,系统会进行元数据校验(如检查时间序列是否存在、数据类型是否匹配)并对数据点按时间戳进行排序,确保时序一致性。
- 内存处理:排序后的数据首先写入内存缓冲区(MemTable)。MemTable采用LSM树(Log-Structured Merge-Tree)结构的思想,当积累到一定阈值或间隔时间后,会异步刷新(Flush)到磁盘形成顺序写的TsFile(时序文件)。此设计极大优化了高吞吐写入性能。
2. 数据查询处理
IoTDB提供了丰富的查询语义,从简单的原始数据点查询到复杂的降采样、聚合、分组计算。
- 查询引擎:解析SQL-like查询语句,生成并优化执行计划。对于涉及多个时间序列或时间段的查询,能有效进行任务分解与并行执行。
- 缓存加速:利用Chunk缓存和Page缓存,将最近访问的TsFile数据块保留在内存,显著减少磁盘I/O,提升高频查询响应速度。
- 计算下推:为减少数据传输开销,聚合(如SUM, AVG)、降采样等计算操作尽可能在数据存储层执行,仅将最终结果返回给客户端。
3. 数据预处理(可选)
在写入前或查询时,可配置数据质量控制(如异常值过滤)和简单转换,但复杂ETL通常建议在接入层完成。
二、数据存储服务
存储服务是IoTDB的基石,其设计深度契合了时序数据“写多读少”、“按时间顺序到达”、“冷热分明”的特点。
1. 存储架构:TsFile 核心
TsFile是IoTDB自研的列式存储文件格式,是其高性能的关键。
- 列式存储:同一设备下不同测点(传感器)的数据分开存储。查询时可按需读取特定列,避免全表扫描,特别适合多维查询场景。
- 内部结构:一个TsFile包含数据区、索引区、元数据区。数据区中,数据按时间序列ID组织,每个序列的数据进一步分成多个“Chunk”(块),每个Chunk包含多个“Page”(页),并支持压缩(如GZIP, LZ4, SNAPPY)。
- 索引加速:文件级索引帮助快速定位查询时间范围所在的Chunk;若启用,还支持二级索引(如标签索引)加速基于设备属性的查询。
2. 分层存储与生命周期管理
IoTDB内置了数据生命周期(TTL)管理机制。
- 热冷数据分离:根据配置策略(通常是时间),将较旧的TsFile从本地SSD/HDD迁移到更廉价的分布式对象存储(如HDFS, S3)或归档存储,实现成本与性能的平衡。
- 数据压缩与合并:后台进程会定期将多个小的、顺序的TsFile合并(Compaction)成更大的文件,清理已删除数据,并进一步优化存储效率和查询性能。
3. 分布式存储(集群版)
在集群部署中,存储服务被分布式化。
- 数据分片(Partitioning):数据可按照时间范围或设备ID进行分片,分布到不同的DataNode上,实现水平扩展。
- 多副本与高可用:每个数据分片在多个DataNode上保存副本(通过Raft协议保证一致性),确保单点故障时数据不丢失、服务不间断。
- 元数据集中管理:ConfigNode负责管理集群元数据(如节点状态、Schema信息),并通过心跳机制监控DataNode健康状态。
三、
IoTDB的数据处理与存储服务紧密协作,形成了一个针对物联网时序数据优化的闭环:
- 写入端:通过内存缓冲与顺序写TsFile,最大化吞吐量。
- 存储层:通过列式存储、高效压缩和智能分层,实现极高的存储压缩比与查询效率。
- 查询端:通过缓存、计算下推和分布式并行处理,满足低延迟分析需求。
理解这套机制,有助于在实际应用中更好地进行模式设计、性能调优与集群规划,从而充分发挥IoTDB在物联网数据管理中的价值。
如若转载,请注明出处:http://www.xinyuan-technology.com/product/74.html
更新时间:2026-06-19 10:42:13